A PDF document is a structure of code and data that must follow certain rules in its structure and syntax to fulfil its objectives:
Its purpose is to transmit information while maintaining its integrity, especially in display and format. It is not originally a format designed for editing.
In order to be independent of the platform on which it is and to maintain that integrity, in principle and if it has not been compressed or encrypted, a PDF is basically an ASCII text file, even if it includes binary data (which are much more compact).
The parts of a PDF

To be valid, a PDF document must have at least the following four parts in this order: (1) Header, (2) Body, (3) Xref (cross reference table) and (4) Trailer.
1. Header
The "header" of a PDF identifies it as a PDF document and declares which version of the format it corresponds to.
It consists of a line starting with "%PDF-" followed by a number identifying the version of the PDF format (the lowest is "1.0", the highest is "2.0"); this is an example of a valid header:
%PDF-1.7
Warning: From version 1.4 of the format, if a different version is indicated in the dictionary called "Catalog", the version existing in this "Catalog" will be used and not the one in the "Header". Without going into details, this is a procedure to ensure backwards compatibility in some programs.
The presence in the "Header" of a second line starting with "%" and some binary characters immediately after has to do with the presence of binary data in the document.
2. Body
The "Body", the most important part of a PDF, contains the description of each of the elements used in the pages. In a PDF, the "Body" is what follows the "Header" and ends with the cross-reference table "Xref". It has no beginning or end mark and it has no defined size. Its limits are set by the presence of these other areas.
The internal organisation of the body, which is absolutely hierarchical, is established neither by the order of appearance nor by the names of the objects contained.
At the top level of the hierarchy there is a root object, which is the "Catalog" dictionary.
3. Cross reference table (xref table)
This part is a table with an entry for each of the programming objects used in the document, indicating their location (that's why the "Body" seems unorganised).
The Cross reference table allows the program interpreting the PDF (for printing or displaying it on screen) to randomly access any element (arrays, Boolean values, numeric values, names, streams, strings and dictionaries) at any time.
It begins by identifying itself with the line "xref".
4. Trailer
The "Trailer of a PDF says to the programme that interprets the document where some essential elements for its reading are located (such as, for example, the cross-reference table and, usually, the root object in the hierarchy of the document).
It starts by identifying itself with the word "Trailer" line and ends with the line "%%EOF", meaning "end of file".
Incrementality and redundancy in PDF structure
Although PDF is not a format devised for editing its content, some provision has been made to allow the alteration of documents (that is, adding or removing pages, adding or removing comments, etc.).

This means that it is a format that allows incremental changes to the structure of a document. Each time data are altered and these changes are saved, a new body, coda and cross-reference tables are created and placed behind the previous ones (which remain as they were).
If these changes are many, the document structure can become very inefficient. Programmes that allow editing of PDF documents often have the ability to optimise the structure of a file to remove these redundancies and simplify the structure again.
Basic components of a PDF
In PDF, data are arranged in basic structures called "objects", as in many programming languages (including PostScript),
The main of these objects are: Arrays, Boolean values, numbers, names, strings, dictionaries and streams. These last two types are perhaps the most important:
The dictionaries
In coding, a dictionary is a table of pairs in which the first term defines a key and the second term defines the value assigned to that key. A dictionary can consist of a single key/value pair or any number of them. The dictionaries are possibly the most characteristic object of the PDF format and many of its elements use this type of structure.
Formally within a PDF, a dictionary is written in the form:
111 222obj<</key1 /Valuer1/key2 666/key3 [0 23 666 35 23 67 98]>>endobj
Where the first line (with two numbers "111 222") is the name of the dictionary and "obj<<" and ">>endobj" define the beginning and the end of the dictionary. Inside, each line forms a key/value pair. The key is defined starting with the slash "/" and the values are defined as character strings (also starting with another slash "/"), a number, an array (with its values in square brackets), etc.
The value of a key can be another dictionary (which is considered a subdictionary). Many of the data and elements in a PDF are organised in dictionaries.
In a dictionary, the key "/Type" always indicates in its value the type of dictionary; for example: "<<.../Type/Pages...>>" indicates that this dictionary contains information about the pages of the document. (There is also the key "/Subtype"). Not all dictionaries have to include them.
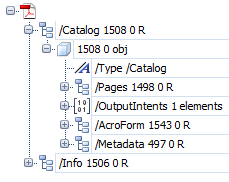
Among the many dictionaries that form a PDF, the following are worth mentioning:
- The Catalog: It provides a direct or indirect reference to all the objects that make up a document (although at the end of the document, in the "
Trailer", there may be some not referred to in this "Catalog". - The Pages: Pages are dictionaries that are organised in a page tree, where minor elements such as images, fonts, texts, etc. are defined or referenced.
The streams
These are byte sequences with no predefined size limit, capable of containing large volumes of data. They must start with a dictionary (defining things like their length or the compression filter used), followed by the word "stream", the bytes that make up the stream and the word "endstream".
The sets of procedures (ProcSets): Within PDF documents, in the resource dictionaries of a stream, we can find structures or elements called "
ProcSets". These are operators inherited by the PDF format from the PostScript language and indicate sets of procedure sets, operations that must only be used when printing on a PostScript device.Since version 1.4 of the PDF format, these procedures are considered obsolete and are only maintained for backwards compatibility with older software and devices.
[© Gustavo Sánchez Muñoz, 2025] Gustavo Sánchez Muñoz (also identified as Gusgsm) is the author of the content of this page. Its graphic and written content can be shared, copied and redistributed in whole or in part without the express permission of its author with the only condition that it cannot be used for directly commercial purposes (that is: It cannot be resold, but it can form part as reasonable quotations in commercial works) and the legal terms of any derivative works must be the same as those expressed in this statement. The citation of the source with reference to this site and its author is not mandatory, although it is always appreciated.